

Inhalt

Carlos Balbach
Consultant
Ihr IT-Systemhaus für ERP und Technologie.
Funktion: manueller Dokument Upload muss ersetzt werden
Unternehmenswissen liegt häufig dort, wo es im Alltag entsteht: in PDF-Dateien, Office-Dokumenten, Tabellen, Präsentationen oder technischen Unterlagen auf gemeinsamen Laufwerken. Diese Dokumente enthalten wertvolle Informationen, werden aber oft nur klassisch abgelegt. Wer später gezielt nach Inhalten sucht, ist oft auf Dateinamen, Ordnerstrukturen oder einzelne Suchbegriffe angewiesen.
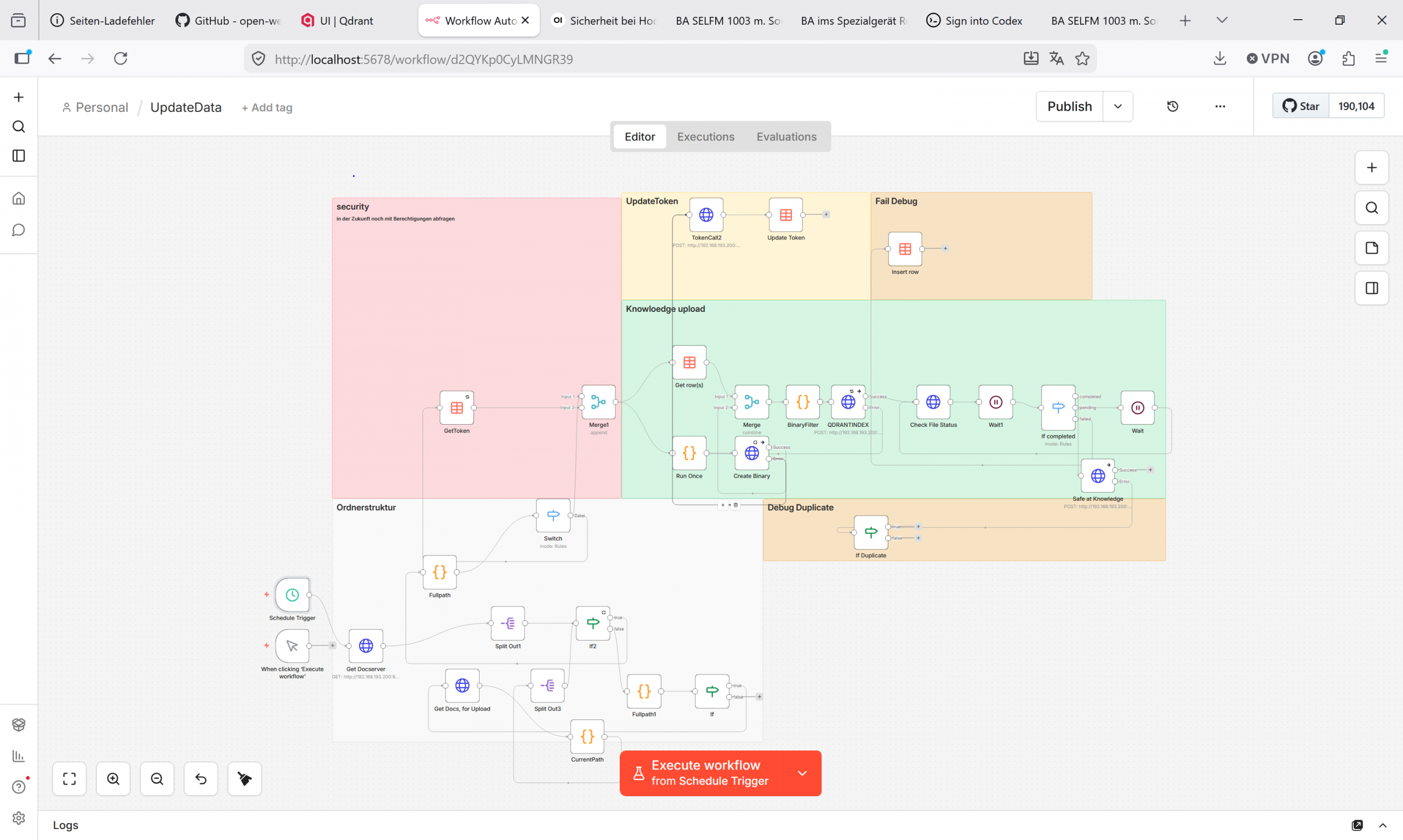
Um dieses Wissen besser nutzbar zu machen, wurde ein automatisierter Prozess aufgebaut, der Unternehmensdokumente aus einer bestehenden Ordnerstruktur erkennt, prüft und für eine intelligente Suche vorbereitet.
Das Ziel besteht darin, Dokumente nicht mehr einzeln manuell hochladen zu müssen. Stattdessen erkennt der Prozess relevante Dateien automatisch, bereitet deren Inhalte auf und stellt sie für ein internes Wissenssystem bereit.
Warum eine semantische Suche?
Eine klassische Suche findet in der Regel nur Begriffe, die exakt eingegeben wurden. Wenn ein Dokument beispielsweise den Begriff „Wartungsplan“ enthält, wird es meist nur dann zuverlässig gefunden, wenn auch genau nach diesem Begriff gesucht wird.
Eine semantische Suche geht einen Schritt weiter. Sie kann Inhalte auch dann finden, wenn die Suchanfrage anders formuliert ist. Wer beispielsweise nach „regelmäßige Instandhaltung“, „jährliche Prüfung“ oder „Wartungsintervall“ sucht, kann trotzdem passende Dokumentstellen finden, auch wenn die Formulierung im Originaldokument abweicht.
Dafür werden Textinhalte technisch so aufbereitet, dass inhaltliche Zusammenhänge maschinell vergleichbar werden. Diese Aufbereitung bildet die Grundlage dafür, relevante Dokumentenabschnitte später gezielt auffindbar zu machen.
Der Prozess im Überblick
Die Automatisierung liest zunächst eine vorhandene Ordnerstruktur aus und prüft, welche Dateien verarbeitet werden können. Unterstützt werden gängige Dokumentformate wie PDF-Dateien, Textdokumente, Tabellen, Präsentationen und strukturierte Textdateien.
Dabei werden automatisch ungeeignete Dateien herausgefiltert. Dazu gehören zum Beispiel temporäre Office-Dateien, leere Dateien oder technische Metadateien, die bei Dateiübertragungen entstehen können. Dadurch wird verhindert, dass unnötige oder fehlerhafte Dateien in den weiteren Prozess gelangen.
Im nächsten Schritt werden die gültigen Dateien an eine interne Verarbeitungskomponente übergeben. Dort werden die Inhalte aus den Dokumenten extrahiert, in kleinere Abschnitte aufgeteilt und für die spätere semantische Suche vorbereitet.
Die erzeugten Suchinformationen werden anschließend in einem spezialisierten Suchindex gespeichert. Dieser Suchindex bildet die technische Grundlage dafür, dass Inhalte später nicht nur über Dateinamen, sondern auch über ihre tatsächliche Bedeutung gefunden werden können.
Wichtig ist dabei: Die Dokumente werden nicht einfach nur abgelegt, sondern inhaltlich strukturiert und für spätere KI-gestützte Abfragen vorbereitet.
Warum nicht alles auf einmal?
Bei kleinen Datenmengen funktioniert eine direkte Verarbeitung meist problemlos. In diesem Projekt geht es jedoch um eine größere Menge an Unternehmensdokumenten. Mehrere tausend Dateien gleichzeitig zu laden, zu übertragen und aufzubereiten, wäre weder stabil noch sinnvoll.
Ein großer Massenlauf kann zu langen Laufzeiten, blockierten Prozessen oder Speicherproblemen führen. Deshalb wurde der Ablauf kontrolliert aufgebaut.
Statt alle Dateien gleichzeitig zu verarbeiten, wird zunächst eine Warteschlange erzeugt. Diese enthält nur die wichtigsten Metadaten der Dateien, zum Beispiel Dateiname, Pfad, Dateityp, Größe und Bearbeitungsstatus.
Die eigentliche Datei wird erst dann verarbeitet, wenn sie an der Reihe ist. Dadurch bleibt der Ablauf stabil, nachvollziehbar und leichter überwachbar.
Jede Datei kann dabei einen Status erhalten, zum Beispiel:
• wartend
• in Bearbeitung
• erfolgreich verarbeitet
• fehlgeschlagen
So ist jederzeit erkennbar, welche Dateien noch ausstehen, welche bereits erfolgreich verarbeitet wurden und bei welchen Dateien ein Fehler aufgetreten ist.
Verarbeitung innerhalb der eigenen Infrastruktur
Ein wichtiger Bestandteil der Lösung ist die Verarbeitung innerhalb der eigenen technischen Umgebung. Die Dokumenteninhalte müssen dadurch nicht an externe Dienste übertragen werden.
Die Aufbereitung der Inhalte erfolgt lokal beziehungsweise innerhalb der kontrollierten Systemumgebung. Dadurch bleiben vertrauliche Unternehmensinformationen im eigenen Einflussbereich.
Das ist besonders wichtig, weil in den Dokumenten interne Abläufe, technische Informationen, Kundendaten, Projektdaten oder betriebliche Unterlagen enthalten sein können.
Die Verarbeitung funktioniert nur zuverlässig, wenn alle internen Komponenten erreichbar sind. Ist eine Verarbeitungskomponente nicht verfügbar, können Dokumente zwar teilweise erkannt oder entgegengenommen werden, aber nicht vollständig für die semantische Suche vorbereitet werden.
Vorteile für das Unternehmen
Durch diesen automatisierten Prozess entsteht eine zentrale Grundlage für ein internes Wissenssystem. Bestehende Dokumente werden nicht nur abgelegt, sondern inhaltlich durchsuchbar gemacht.
Das ist besonders wertvoll für technische Dokumentationen, Betriebsanleitungen, Wartungsunterlagen, Prozessbeschreibungen, Projektunterlagen oder Schulungsmaterialien. Mitarbeitende müssen künftig nicht mehr wissen, in welchem Ordner ein Dokument liegt oder wie es exakt benannt wurde. Stattdessen kann über Inhalte gesucht werden.
Auch für KI-gestützte Assistenzsysteme ist diese Struktur wichtig. Ein interner Assistent kann später gezielt relevante Dokumentenabschnitte aus dem Wissensbestand abrufen und auf dieser Grundlage Antworten formulieren. Das reduziert fehlerhafte oder ungenaue Antworten, weil die Antworten stärker auf vorhandenen Unternehmensinformationen basieren.
Fazit
Mit dem automatisierten Verarbeitungsprozess wurde eine robuste Grundlage geschaffen, um internes Unternehmenswissen besser nutzbar zu machen.
Die Lösung erkennt relevante Dokumente automatisch, filtert ungeeignete Dateien aus, verarbeitet Inhalte kontrolliert und stellt sie für eine semantische Suche bereit.
Der große Vorteil liegt nicht nur in der Automatisierung selbst, sondern auch in der kontrollierten Verarbeitung. Durch die Warteschlangen-Struktur können große Dokumentenmengen schrittweise verarbeitet werden, ohne das System unnötig zu belasten.
Damit entsteht ein skalierbarer Weg, vorhandene Unternehmensdokumente für moderne interne Wissens- und Assistenzsysteme bereitzustellen.
Unsere AI Lösung LLia
Holen Sie sich auch die neuesten Informationen zu unserer KI-Lösung LLia powered by MJR.

Jetzt direkt Kontakt aufnehmen
Michael Raber
General Manager



