

Inhalt

Carlos Balbach
Consultant
Your partner for ERP and technology.
Functionality: Manual document upload needs to be replaced
Organizational knowledge is often found where it is created in day-to-day operations: in PDF files, Office documents, spreadsheets, presentations, or technical documents stored on shared drives. These documents contain valuable information but are often simply filed away in the traditional way. Anyone searching for specific content later on is often limited to file names, folder structures, or individual search terms.
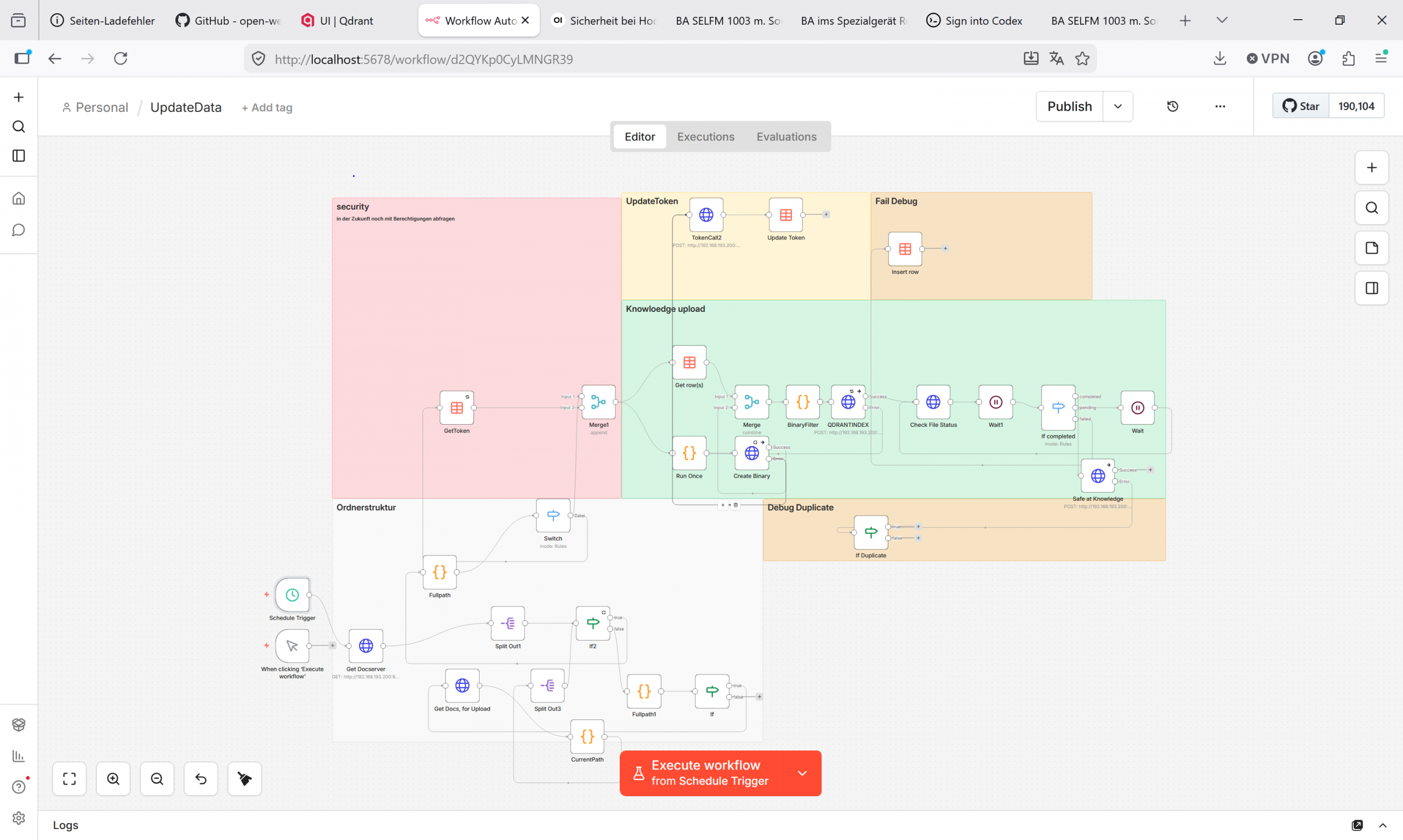
To make this knowledge more accessible, an automated process was developed that identifies corporate documents from an existing folder structure, verifies them, and prepares them for intelligent search.
The goal is to eliminate the need to manually upload documents one by one. Instead, the process automatically identifies relevant files, processes their content, and makes them available for an internal knowledge management system.
Why semantic search?
A traditional search typically finds only terms that have been entered exactly as they appear. For example, if a document contains the term “maintenance schedule,” it will usually be found reliably only if the search is performed using that exact term.
A semantic search goes one step further. It can find content even if the search query is phrased differently. For example, someone searching for “regular maintenance,” “annual inspection,” or “maintenance interval” can still find relevant document sections, even if the wording in the original document differs.
To achieve this, text content is technically processed in such a way that contextual relationships become machine-comparable. This processing forms the basis for making relevant document sections specifically searchable later on.
Overview of the Process
The automation first scans an existing folder structure and checks which files can be processed. It supports common document formats such as PDF files, text documents, spreadsheets, presentations, and structured text files.
Unsuitable files are automatically filtered out. These include, for example, temporary Office files, empty files, or technical metadata files that may be generated during file transfers. This prevents unnecessary or corrupted files from entering the subsequent process.
In the next step, the valid files are transferred to an internal processing component. There, the content is extracted from the documents, divided into smaller sections, and prepared for later semantic search.
The generated search information is then stored in a specialized search index. This search index forms the technical foundation that enables content to be found later not only by filename but also by its actual meaning.
It is important to note that the documents are not simply stored but are structured by content and prepared for later AI-powered queries.
Why not do it all at once?
Each file can be assigned a status, for example:
• waiting
• in process
• successfully transferred
• failed
This makes it easy to see at any time which files are still pending, which have already been processed successfully, and which ones encountered an error.
Processing within our own infrastructure
An important component of the solution is processing within the organization’s own technical environment. This eliminates the need to transfer document content to external services.
Content processing takes place locally or within a controlled system environment. As a result, confidential company information remains within the organization’s control.
This is particularly important because documents may contain internal processes, technical information, customer data, project data, or operational records.
Processing only works reliably if all internal components are accessible. If a processing component is unavailable, documents can be partially recognized or received, but cannot be fully prepared for semantic search.
Benefits for the company
This automated process creates a central foundation for an internal knowledge management system. Existing documents are not merely archived but made searchable by content.
This is particularly valuable for technical documentation, operating manuals, maintenance records, process descriptions, project documents, and training materials. In the future, employees will no longer need to know which folder a document is in or its exact filename. Instead, they can search by content.
This structure is also important for AI-powered assistance systems. An internal assistant can later retrieve specific relevant document sections from the knowledge base and formulate answers based on them. This reduces erroneous or inaccurate answers because the responses are more strongly grounded in existing company information.
Conclusion
The automated processing workflow has created a solid foundation for making better use of internal company knowledge.
The solution automatically identifies relevant documents, filters out unsuitable files, processes content in a controlled manner, and makes it available for semantic search.
The major advantage lies not only in the automation itself, but also in the controlled processing. Thanks to the queue structure, large volumes of documents can be processed incrementally without placing an unnecessary burden on the system.
This provides a scalable way to make existing company documents available for modern internal knowledge and assistance systems.
AI Solution LLia
Also check out the latest details about our AI solution LLia powered by MJR.

Just contact us
Michael Raber
General Manager






